Stream Data Model
Contents
Stream Data Model#
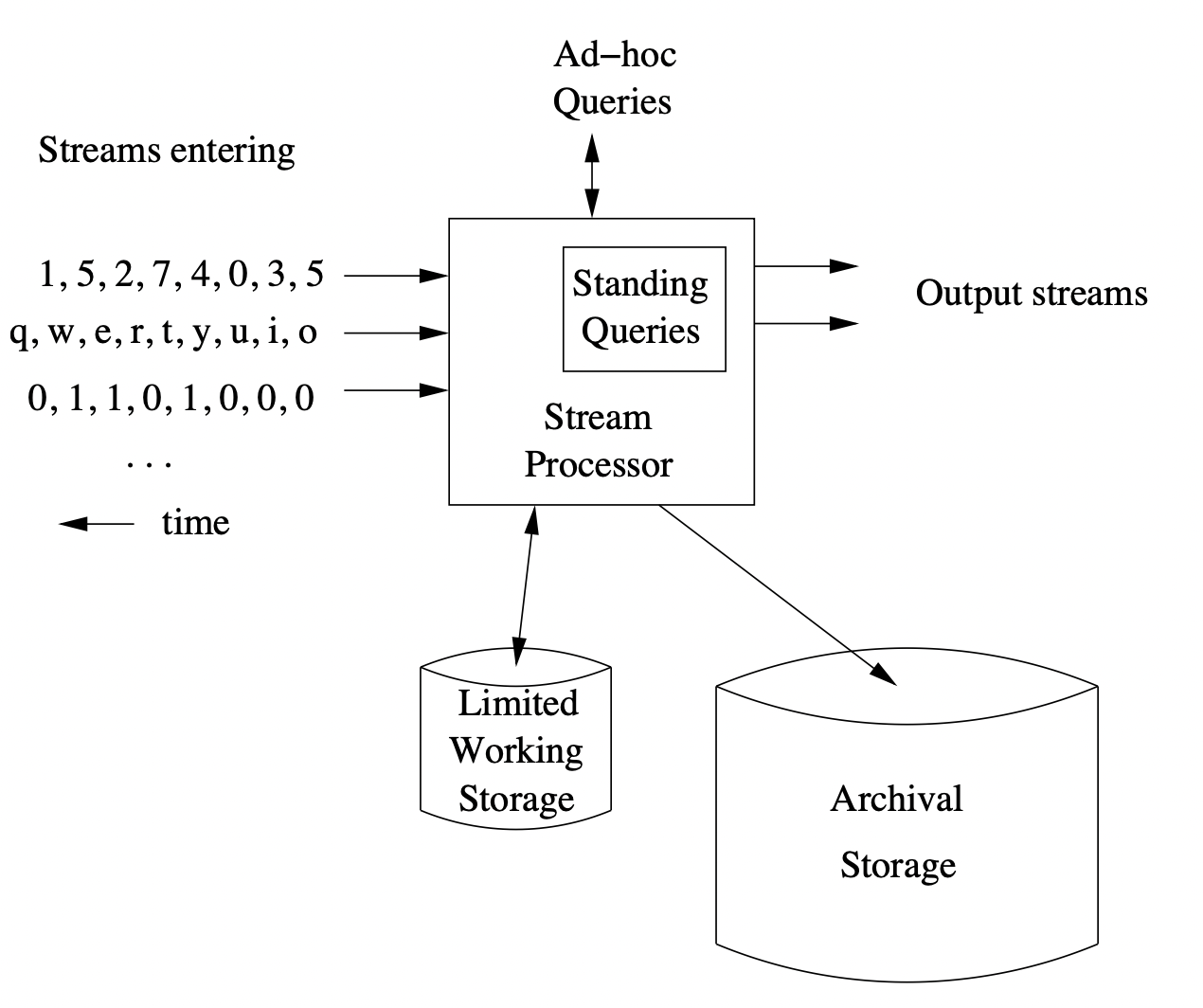
Fig. 7 A canonical example of a streaming data management system.#
We show a canonical example of a streaming data management system above (See Fig. 7). A number of stream is feeeing into the system, each providing data on its own schedule. The data from the stream need be uniform both in the data type and the rate at which the data arrives. The fact that the rate of arrival of stream elements is not under the control of the system is the main distinguishing factor between stream mining and a regular data mining system.
Streams may eventually be saved in a longer term archival storage like a disk or database, but we have to assume that we cannot answer analytics queries using the archived data because retrieving it is a time-consuming process and the latency of the streaming data coming in is much faster. Instead there is a limited working storage which can be accessed faster that we can use, but it has insufficient capacity to store the entire stream.
Stream Sources#
Sensor Data
Video Cameras
Internet Web Traffic
Server Logs
Stream Queries#
There are two main types of queries we want to make of streaming data. The first are standing queries which are permanently executing. For example if we have streaming data from temperature sensors, our standing queries could be:
Output alerts when temperature data passes a certain threshold.
Average temperature using the last \(n\) elements in a stream.
What’s the maximum temperature ever recorded in the stream
All of these are calculations that can be done quickly when new data appears in the stream with no store the stream in its entirety.
The other form of queries are adhoc queries. Here the queries can be one-time or the parameter of the query can be changing based on the need. A common approach would be to store a sliding window of the \(n\) most recent data in the working storage of the stream management system.
Examples of Stream Processing Systems#


Two examples of streaming systems are: Apache Kafka (https://kafka.apache.org) and Amazon Kinesis (https://aws.amazon.com/kinesis/). For the examples in this notebook we will Apache Kafka to simulate data coming from a stream.
import numpy as np
import sys
import hashlib
import random
import math
import dask.array as da
import dask.dataframe as dd
random.seed(10) #Set seed for repeatability
#Hash a string to an integer
def hashInt(val, buckets=sys.maxsize, hashType='default'):
if hashType == 'default':
return hash(val) % buckets
elif hashType == 'md5':
return hash(hashlib.md5(val.encode('utf-8')).hexdigest()) % buckets
#Hash a string to a bit string
def hashBits(val, hashType='default'):
if hashType == 'default':
return bin(hash(val))
elif hashType == 'md5':
return bin(hash(hashlib.md5(val.encode('utf-8')).hexdigest()))
words = np.array(open('words.txt').read().splitlines())
userIds = np.arange(1, 1000)
Kafka Example#
import kafka
#Build our streams
words = np.array(open('words.txt').read().splitlines()) #copied from /usr/share/dict/words
userIds = np.arange(1, 1000)
producer = kafka.KafkaProducer()
#Create streams of 2 million elements
for i in range(1000000):
if (i+1) % 100000 == 0:
print(i+1)
producer.send('sampling', (str(np.random.choice(words))).encode('utf-8'))
producer.flush()
producer.close()
consumer = kafka.KafkaConsumer('test', auto_offset_reset='earliest')
n = 0
for msg in consumer:
print(msg.value.decode("utf-8"))
n += 1
if n == 8:
break
consumer.close()
Exercise#
What other streaming use cases can you think of?
Research other streaming data libraries and systems.