LSH Banding Technique
LSH Banding Technique#
In this section, we discuss the more traditional approach to LSH which follows the workflow of shingling \(\rightarrow\) minhashing \(\rightarrow\) banding (the actual LSH step).
Recall: We can express documents as k-shingles (or whichever token we choose) and consequently perform a mminhashing to obtain signatures. We arrange these into columns of a matrix–where rows correspond to each item of a signature. Also, suppose that the signatures now have invariant lengths (i.e., number of rows) due to the prior ‘preprocessing’ done.
We obtain a structure similar to what is shown below:
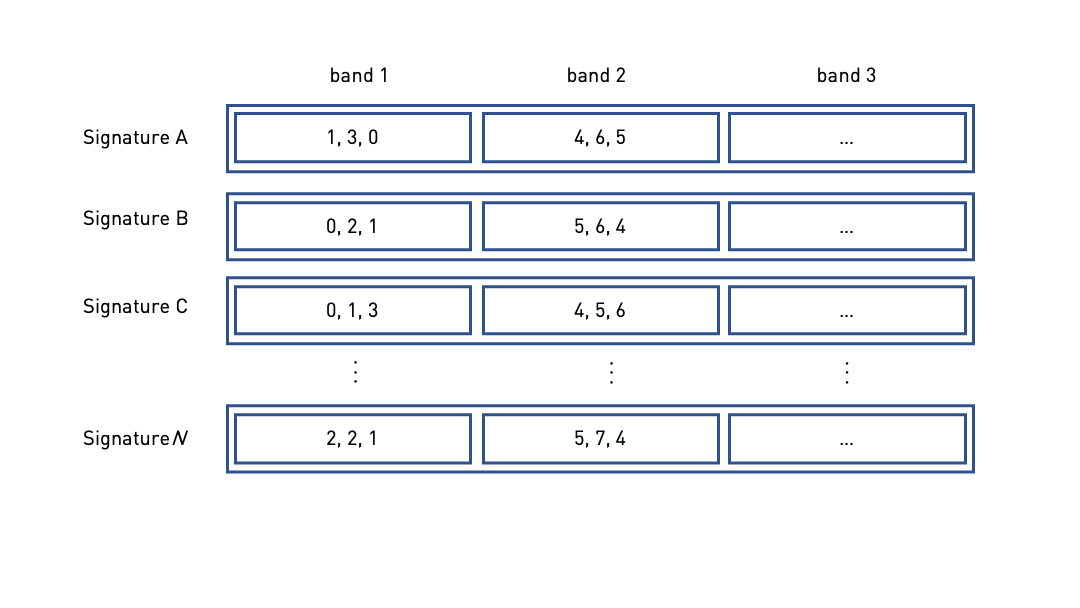
Fig. 5 Segmented signature matrix. Four segments/bands with three rows per segment. Taken from [RU11].#
Notice that unlike those discussed in Minhashing, this signature matrix are now segmented into bands containing three (3) rows per band. Why do this?
Let’s break it down. If we simply apply a hash function to full signatures then it will most likely be that we will only get the completely identical signatures–losing pairs that hold some similarity (i.e., candidate pairs) in some segments of their respective signatures. Note: We end up discarding similar but not identical documents. This presents another compelling reason for the banded LSH approach.
A natural course to this is to “hash” the items several times using different hash functions banking on the idea that similar items will more likely be hashed to the same bucket–otherwise, dissimilar items. The book terminology for items hashed into the same buckets are candidate pairs. Narrowing down the search? Voila! Candidate pairs instead of that \(n \choose 2\) number of pairs.
Alternatively, for minhashed signatures like the one shown in Fig. 5, hashing can be applied per band/segment. Hash functions can either be varied per band/segment or the same. In effect, multiple hashing and/or segmented hashing addresses the overfit on getting only identical but not similar items.
Banded signatures are then hashed, forming different hash tables for each band. Candidate pairs are then determined according to those hashed in the same buckets. See Fig. 6 for the underlying mechanics.
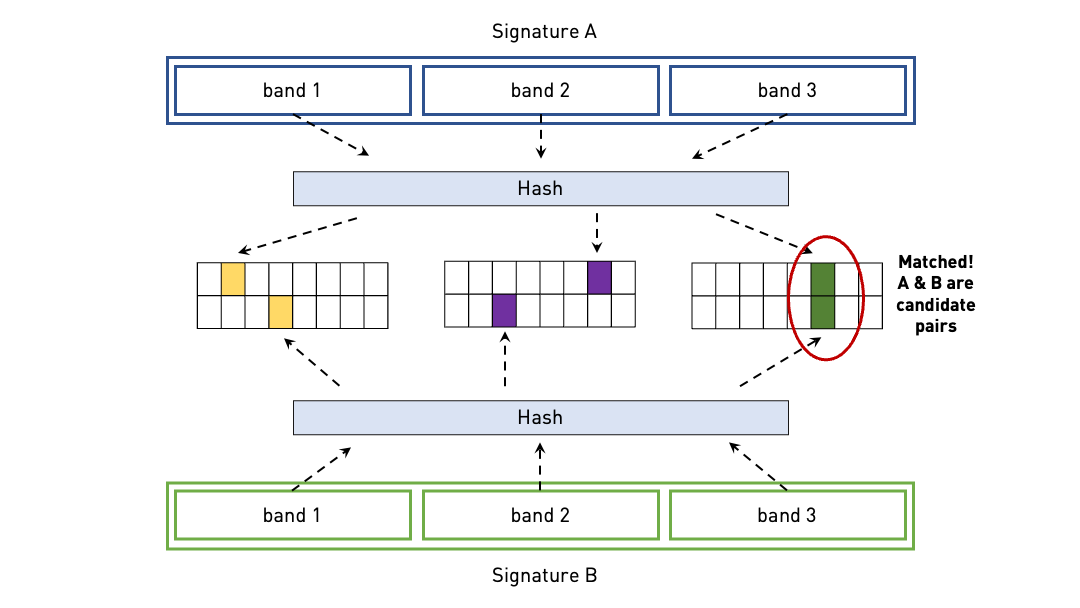
Fig. 6 Underlying mechanics of the “Band Hashing” method for two banded signature sets \(a\) and \(b\). In this figure, A and B are considered as candidate pairs because their 3rd bands are hashed in the same buckets. Here only one hash function is used but bands get their own set of hash buckets.#
Following a more tolerant approach wherein any pair are classified as candidate pairs as long as they are hashed in the same bucket in any of the bands formed, hence number of bands and the resulting number of rows in each band as a tuning parameter. Wherein more number of bands will increase the probability of any pair–despite having low similarity–to be tagged as candidate pairs. We then state that the number of bands determine the similarity threshold as shown below–where document pairs with pairwise similarities above the threshold (dashed line) will be tagged as candidate pairs.
# from plotly.offline import init_notebook_mode, iplot
# init_notebook_mode()
import plotly.graph_objs as go
import numpy as np
def _get_factors(x):
factors = []
for i in range(1, x + 1):
if x % i == 0:
factors.append(i)
return factors
def _get_valinit(factors):
index = len(factors) // 2
return factors[index]
def _prob_of_s(s, b, r):
"""Return the probability of similarity s given b and r"""
return 1 - (1 - s**r)**b
def _get_approx_thresh(b, r):
"""Return approximate similarity threshold for chosen b and r"""
thresh = (1/b) ** (1/r)
return thresh
m = 100 # signature size
b_list = _get_factors(m) # list of possible b-values
s_list = np.linspace(0, 1, num=100)
p_lists = [np.array([_prob_of_s(s, b, r=m/b) for s in s_list]) for b in b_list]
thresh_list = [_get_approx_thresh(b, r=m/b) for b in b_list]
data = [
go.Scatter(
visible=False,
line=dict(color="deeppink", width=6),
x=s_list,
y=p_list)
for p_list in p_lists
]
vlines = [
go.layout.Shape({
'line': {'dash': 'dash', 'width': 2.5},
'type': 'line',
'visible': False,
'x0': thresh,
'x1': thresh,
'xref': 'x',
'y0': 0,
'y1': 1,
'yref': 'y domain'})
for thresh in thresh_list
]
annots = [
go.layout.Annotation({
'font': {'size': 12},
'showarrow': False,
'text': f'Similarity Threshold {thresh:.2f}',
'visible': False,
'x': 0,
'xanchor': 'left',
'xref': 'x',
'y': 1,
'yanchor': 'top',
'yref': 'y domain'})
for thresh in thresh_list
]
mid_index = len(b_list) // 2 # start index
data[mid_index]["visible"] = True
vlines[mid_index]["visible"] = True
annots[mid_index]["visible"] = True
layout = go.Layout(
title={'text': f"""Probability of becoming a candidate given a similarity<br>The S-curve at {b_list[mid_index]} bands with signature size {m}"""},
annotations=annots,
shapes=vlines,
)
fig = go.Figure(data=data, layout=layout,)
steps = []
for i in range(len(data)):
title = f"""Probability of becoming a candidate given a similarity<br>The S-curve at {b_list[i]} bands with signature size {m}"""
shape_args = {f"shapes[{idx}].visible":idx==i for idx in range(len(fig.data))}
annotation_args = {f"annotations[{idx}].visible":idx==i for idx in range(len(fig.data))}
layout_args = {"title.text": title}
layout_args.update(shape_args)
layout_args.update(annotation_args)
step = dict(
method='update',
args=[
# trace updates
{'visible': [t == i for t in range(len(data))]},
# layout updates
layout_args,
],
label=f"{b_list[i]}"
)
step["args"][0]["visible"][i] = True
steps.append(step)
sliders = [
go.layout.Slider(
active=mid_index,
currentvalue={"prefix": "Number of bands: "},
pad={'t':50},
steps=steps
)
]
fig.layout.xaxis.title = 'Jaccard Similarity of Documents'
fig.layout.yaxis.title = 'Probability'
fig.update_layout(
sliders=sliders
)
fig
# iplot(fig)