ReSyPE Training Pipeline¶
We introduce a framework for training arbitrary machine learning models to perform collaborative filtering on small and large datasets. Given the utility matrix as input, we outline two approaches for model training as discussed by C. Aggarwal in his book on Recommender Systems. We also propose an extension of these methodologies by applying clustering on the dataset before the model training.
Machine Learning + Collaborative Filtering (ML+CS) Recommender System¶
Approach 1: ML-based Collaborative Filtering on Utility Matrix with Reduced Dimensions¶
Fill Utility Matrix with mean of matrix
Choose column j to where missing ratings will be predicted. Column j will be the label in the model while the features will be the rest of the columns (not equal to j).
Perform SVD on feature matrix. This will be the new feature table used to predict the ratings for item j.
Train a model using the feature matrix as input and column j as output
Repeat 2, 3, 4 for all items/columns.
Approach 2: Iterative Approach to ML-based Item-wise Collaborative Filtering¶
Mean-center each row of the utility matrix to remove user bias.
Replace missing values with zero after mean centering.
Choose column j to where missing ratings will be predicted. Column j will be the label in the model while the features will be the rest of the columns (not equal to j).
Train a model using the feature matrix as input and column j as output
Predict missing ratings for column j.
Use the predicted values to update the missing ratings in the utility matrix.
Perform steps 3, 4, 5, 6 for all columns.
Iterate steps 3 to 7 until the predicted ratings converge.
Approach 3: ML and Content-Based Collaborative Filtering¶
Generate user features and item features
Concatenate the user features and item features for every user-item pair wherein a user has rated an item.
Perform a stratified splitting of the data into train and test sets where the test set is a fraction of the items a user has not rated. Each user must have a minimum number of items rated to be part of the training process.
Train a model using the concatenated user-item feature table to predict the rating for each user-item pair in the training set.
Use the trained model to predict the rating for all items a user has not rated.
Select the items with the highest rating as the recommendations.
Training on Large Datasets¶
The diagram below shows the flowchart of the proposed method for model training. If the dataset is small (left branch), we use the two approaches metioned above and apply them to the raw utility matrix. Since we are training one model per item, a limitation of these methods is that they are computationally expensive especially when the iterative approach is used. Hence we need a more scalable solution. One way to do this assigning users and/or items into clusters and deriving a new utility matrix that contains the representative ratings per cluster.
After clustering, the cluster-based utility matrix contains the aggregate ratings of each cluster. The collaborative filtering problem is now reduced to prediction of ratings per user- or item-cluster instead of predicting the ratings for all users and items.
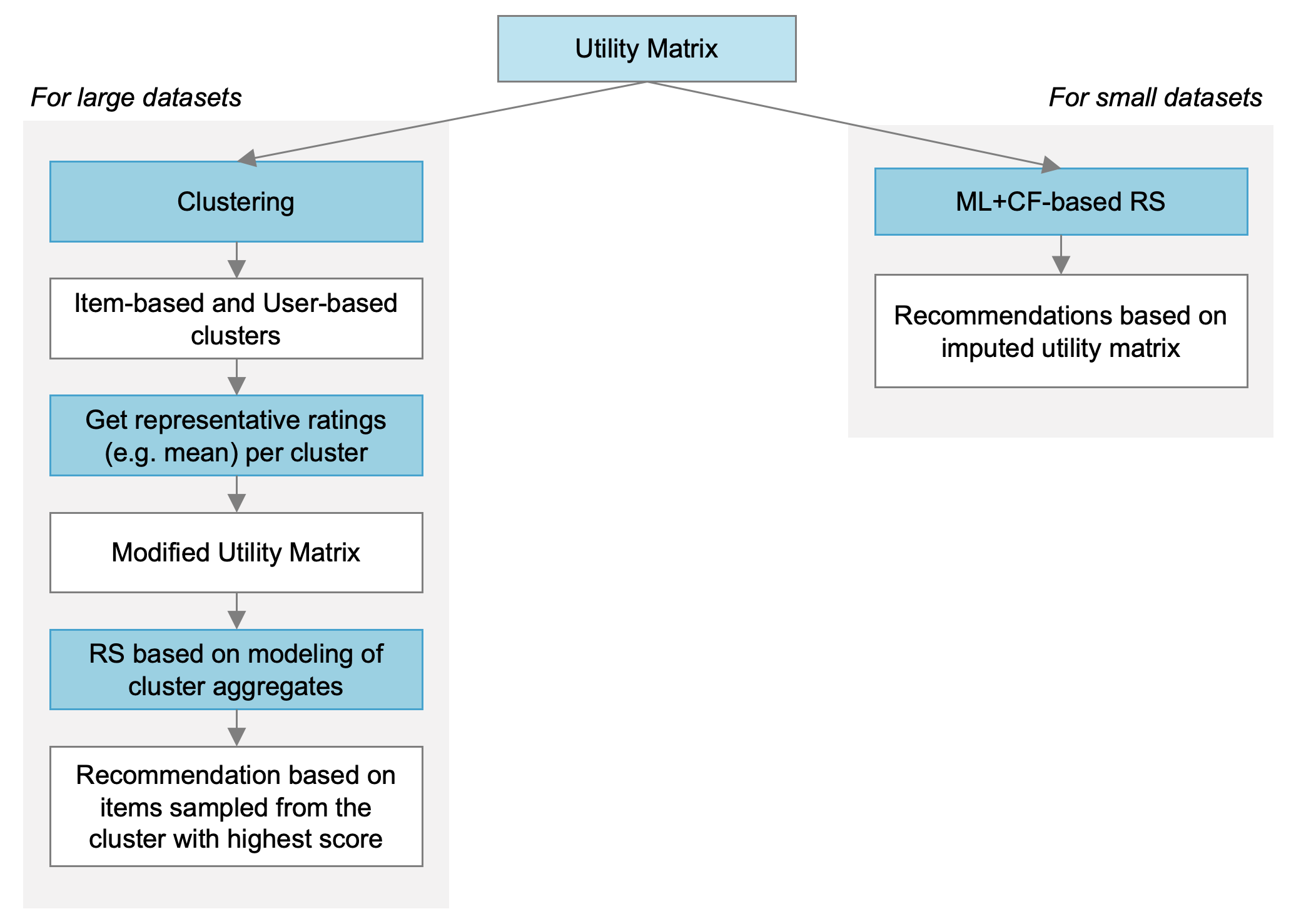
Model training for clustered data¶
Generate multiple sets of synthetic data containing unknown/missing ratings. We do this by randomly setting elements of the cluster-based utility matrix to NaN.
For each matrix of synthetic data, we apply the iterative and the SVD approach to predict the missing ratings.
Get all predictions from each matrix of synthetic data and get the mean across all datasets. This will be the treated as the final cluster-based predictions of the RS.